算法 - (数组、链表)
数组、链表是编程语言中最常见的数据结构,也是最基础的数据结构。以下会以几道 LeetCode 巩固自己的基础
结构对比
数组和链表各有各的优势,比如数组的随机插入和删除都是O(n)的,可谓是很低效了。但是数组的查找是是O(1),直接指定下标即可找到对应的元素。而链表必须遍历,也就是想要查找你一个元素的时间复杂度是 O(n)。所以数组和链表各有各的优势,互相补充。
| 数据结构 | 操作 | 时间复杂度 |
|---|---|---|
| 数组 | prepend | O(1) |
| append | O(1) | |
| lookup | O(1) | |
| insert | O(n) | |
| delete | O(n) | |
| – | – | |
| 链表 | prepend | O(1) |
| append | O(1) | |
| lookup | O(n) | |
| insert | O(1) | |
| delete | O(1) |
数组
a := []int{1, 1, 2, 2, 2, 3, 4, 5, 5, 5, 6}
var b []int
b = append(c, 11)
b = append(b, a...)
// make( []Type, size, cap )
// 其中 Type 是指切片的元素类型,
// size 指的是为这个类型分配多少个元素,cap 为预分配的元素数量,
// 这个值设定后不影响 size,只是能提前分配空间,降低多次分配空间造成的性能问题。
c := make([]int, 2, 10)
链表
// 定义单链表
type ListNode struct {
Val int
Next *ListNode
}
func (ln *ListNode) add(v int) {
if ln == nil {
ln = &ListNode{Val: v,Next: nil}
}
for ln.Next != nil {
ln = ln.Next
}
ln.Next = &ListNode{Val: v,Next: nil}
}
func (ln *ListNode) traverse() {
for ln != nil {
fmt.Printf("%d ",ln.Val)
ln = ln.Next
}
}Leetcode
数组
No.1 两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
func twoSum(nums []int, target int) []int {
tmp := make(map[int]int, len(nums)/2)
for i := 0;i < len(nums);i++ {
if index, ok := tmp[target-nums[i]]; ok {
return []int{index,i}
}
tmp[nums[i]] = i
}
return []int{}
}No.3 无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。 示例1:输入: s = “abcabcbb” 输出: 3 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
首先需要明确, 无重复字符串是什么意思。 awwke , 最长无重复子串是 wke ,因为 ww 重复了!!
func lengthOfLongestSubstring(s string) int {
if len(s) == 0 {
return 0
}
checkFunc := func(sub string) bool {
m := make(map[byte]struct{})
for i := 0 ; i < len(sub); i++ {
if _, ok := m[sub[i]]; ok {
return false
} else {
m[sub[i]] = struct{}{}
}
}
return true
}
maxLength := 1
for i := 0; i < len(s); i++ {
for j := i; j < len(s); j ++ {
subStr := s[i:j+1]
if checkFunc(subStr) {
if len(subStr) > maxLength {
maxLength = len(subStr)
}
}
}
}
return maxLength
}看了一下官方题解,原来是要搞个滑动窗口。
- 首先,用一个map表示滑动窗口。
- 不断移动右指针,当出现某个字符不为0时,证明子串里有重复了(map 里面已经存过了)。
- 重复的肯定是左指针指向的值,所以删除左指针所指的值,保持滑动窗口向前滑动。
- 直到计算出最大子串的值
func lengthOfLongestSubstring(s string) int {
right := 0
// 用于存当前窗口中都有哪些字符,当map的value不为1时,表示需要滑动了
storeMap := make(map[byte]int)
max := 0
for left := 0; left < len(s); left++ {
// 左指针向前移动一下,消除窗口中的重复值
if left != 0 {
delete(storeMap, s[left-1])
}
for ; right < len(s); right++ {
// 为0表示是新元素
if storeMap[s[right]] == 0 {
storeMap[s[right]]++
} else {
break
}
}
// 窗口中存在重复字符串了(或者遍历完了数组), 且肯定出现的重复字符是最早加入的(left所指的值)
if max < right-left {
max = right - left
}
}
return max
}No.4 寻找两个正序数组的中位数
链接:https://leetcode.cn/problems/median-of-two-sorted-arrays/
思路:使用二分查找在较短数组上找分割点,使得左半部分最大值≤右半部分最小值。通过调整分割点位置保证平衡分割,最终根据总长度奇偶性计算中位数。时间复杂度O(log(min(m,n)))。
给定两个大小分别为
m和n的正序(从小到大)数组nums1和nums2。请你找出并返回这两个正序数组的 中位数 。算法的时间复杂度应该为
O(log (m+n))。示例 1:
输入:nums1 = [1,3], nums2 = [2] 输出:2.00000 解释:合并数组 = [1,2,3] ,中位数 2示例 2:
输入:nums1 = [1,2], nums2 = [3,4] 输出:2.50000 解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
func findMedianSortedArrays(nums1 []int, nums2 []int) float64 {
// 确保nums1是较短的数组
if len(nums1) > len(nums2) {
nums1, nums2 = nums2, nums1
}
m, n := len(nums1), len(nums2)
left, right := 0, m
for left <= right {
// nums1的分割点
i := (left + right) / 2
// nums2的分割点,保证左半部分元素总数 = (m+n+1)/2
j := (m+n+1)/2 - i
// 边界值处理
maxLeft1 := -1<<31 // 负无穷
if i > 0 {
maxLeft1 = nums1[i-1]
}
minRight1 := 1<<31 - 1 // 正无穷
if i < m {
minRight1 = nums1[i]
}
maxLeft2 := -1<<31 // 负无穷
if j > 0 {
maxLeft2 = nums2[j-1]
}
minRight2 := 1<<31 - 1 // 正无穷
if j < n {
minRight2 = nums2[j]
}
// 检查分割是否正确
if maxLeft1 <= minRight2 && maxLeft2 <= minRight1 {
// 找到正确的分割
if (m+n)%2 == 0 {
// 总长度为偶数
return float64(max(maxLeft1, maxLeft2)+min(minRight1, minRight2)) / 2.0
} else {
// 总长度为奇数
return float64(max(maxLeft1, maxLeft2))
}
} else if maxLeft1 > minRight2 {
// nums1分割点太靠右
right = i - 1
} else {
// nums1分割点太靠左
left = i + 1
}
}
return 0.0
}No.5 最长回文子串
- 链接:https://leetcode.cn/problems/longest-palindromic-substring/
- 思路:这道题就是一个长串里找回文子串,使用中心扩展法。
给你一个字符串 s,找到 s 中最长的 回文 子串。 示例 1:
输入:s = “babad” 输出:“bab” 解释:“aba” 同样是符合题意的答案。 示例 2:
输入:s = “cbbd” 输出:“bb”
func longestPalindrome(s string) string {
if len(s) <= 1 {
return s
}
longestStr := ""
for i := 0; i < len(s); i++ {
str1 := helper(s, i, i+1) // 考虑 abba 形式
str2 := helper(s, i, i) // 考虑 aba 形式
if len(longestStr) < len(str1) {
longestStr = str1
}
if len(longestStr) < len(str2) {
longestStr = str2
}
}
return longestStr
}
// 查找最长子串
func helper(s string, left, right int) string {
var str string
for ; left >= 0 && right <= len(s)-1 && s[left] == s[right]; left, right = left-1, right+1 {
str = s[left : right+1]
}
return str
}No.11 盛最多水的容器
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。
- 数组从两边开始向中间凑。选出一个最大的面积。
func maxArea(height []int) int {
maxV := 0
left, right := 0, len(height)-1
for left < right {
if height[left] > height[right] {
maxV = max((right-left) * height[right], maxV)
// 左边更高,右边左移
right --
} else {
maxV = max((right-left) * height[left], maxV)
// 右边更高,左边右移动
left ++
}
}
return maxV
}No.15 三数之和
- 链接:https://leetcode.cn/problems/3sum/
- 思路:先将数组排序,再2层循环。如[-1,0,1,2,-1,-4 ] 先排序,排序之后 [-4, -1, -1, 0, 1, 2] 数组,再进行一次双重循环,第一次取 -4 ,再对 -4 之后的数组进行一次循环,-4 + 数组头元素 + 数组尾元素 > 0 就证明,数组尾元素过大, < 0 就证明数组头元素太小。逐渐的收拢第二个数组。
func threeSum(nums []int) [][]int {
sort.Ints(nums)
validNums := make(map[[3]int]struct{})
for i := 0; i < len(nums)-2; i++ {
minNum := nums[i]
midNumIndex := i + 1
maxNumIndex := len(nums) - 1
// 中间索引 小于 最大索引
for midNumIndex < maxNumIndex {
midNum := nums[midNumIndex]
maxNum := nums[maxNumIndex]
// 大于0了,证明最大的数太大了
if minNum+midNum+maxNum > 0 {
maxNumIndex--
continue
}
// 小于0了,证明中间数太小了
if minNum+midNum+maxNum < 0 {
midNumIndex++
continue
}
// 只能是等于 0 了, 中间数加点,最大数减点,看看是否还能拼出0
if minNum+midNum+maxNum == 0 {
validNums[[3]int{minNum, midNum, maxNum}] = struct{}{}
midNumIndex++
maxNumIndex--
}
}
}
var res [][]int
for k, _ := range validNums {
res = append(res, []int{k[0], k[1], k[2]})
}
return res
}No.20 有效的括号
- 链接: https://leetcode.cn/problems/valid-parentheses/description/
- 思路: 使用栈数据结构:遇到左括号入栈,遇到右括号检查栈顶是否匹配并出栈,最后栈为空则有效。时间复杂度O(n),空间复杂度O(n)。
给定一个只包括
'(',')','{','}','[',']'的字符串s,判断字符串是否有效。有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
package main
import "fmt"
func isValid(s string) bool {
stack := []rune{}
mapping := map[rune]rune{
')': '(',
'}': '{',
']': '[',
}
for _, char := range s {
if char == '(' || char == '{' || char == '[' {
// 左括号入栈
stack = append(stack, char)
} else {
// 右括号
if len(stack) == 0 {
return false
}
// 检查栈顶是否匹配
if stack[len(stack)-1] != mapping[char] {
return false
}
// 匹配成功,出栈
stack = stack[:len(stack)-1]
}
}
// 栈为空说明所有括号都匹配
return len(stack) == 0
}No.26 删除排序数组中的重复项
func removeDuplicates(nums []int) int {
if len(nums) == 0 {
return 0
}
slow := 1
for fast := 1; fast < len(nums); fast++ {
if nums[fast] != nums[fast-1] {
nums[slow] = nums[fast]
slow++
}
}
return slow
}思路2: 旋转数组法 旋转数组应该是我比较喜欢的一种方式,比较简单,那就是数组翻转2次,可以将首位数转到末尾曲,重复项判断刚好使用这种方式,对于移动数组类的题是比较通吃的一个方法问题就是时间复杂度比较大
func reversal(nums []int) {
length := len(nums)
for i := 0; length > 1 && i < length/2; i ++ {
nums[i],nums[length-1-i] = nums[length-1-i],nums[i]
}
}
func removeDuplicates(nums []int) int {
length := len(nums)
for i := 0; i < length; i ++ {
if i + 1 < length && nums[i] == nums[i+1] {
reversal(nums[i+1:length])
reversal(nums[i+1:length-1])
length = length - 1
i = i - 1
}
}
return length
}No.27 移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。
func removeElement(nums []int, val int) int {
slow := 0
for fast := 0; fast < len(nums); fast++ {
if nums[fast] != val {
nums[slow] = nums[fast]
slow++
}
}
return slow
}No.29 顺时针打印矩阵
螺旋遍历:从左上角开始,按照 向右、向下、向左、向上 的顺序 依次 提取元素,然后再进入内部一层重复相同的步骤,直到提取完所有元素。 示例 1:
输入:array = [[1,2,3],[8,9,4],[7,6,5]] 输出:[1,2,3,4,5,6,7,8,9]
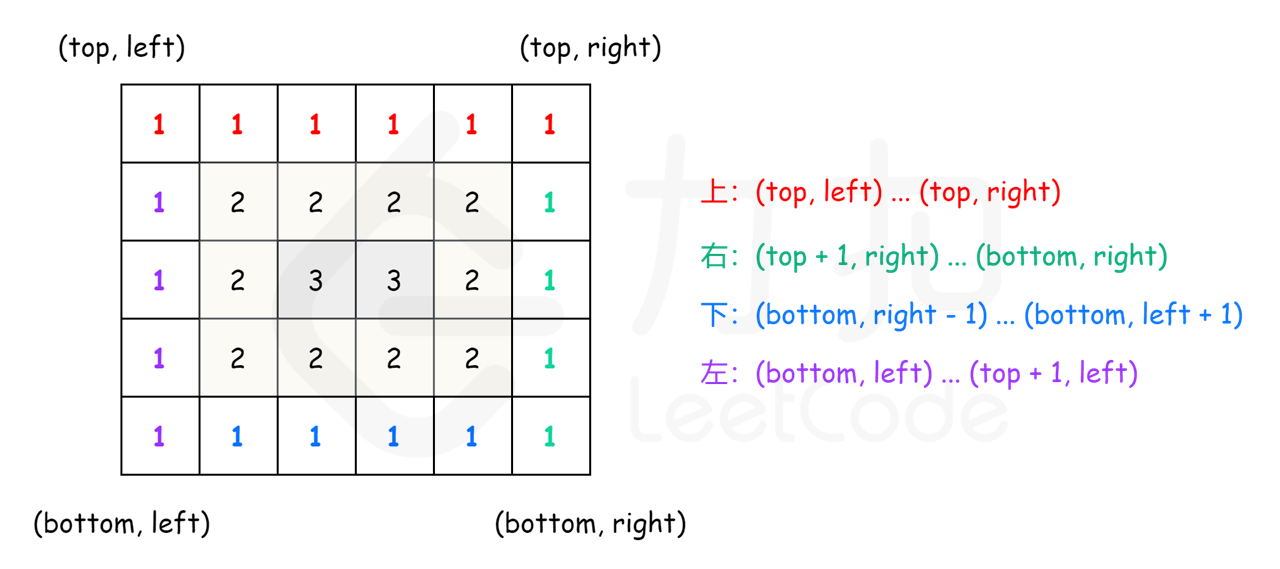
func spiralOrder(matrix [][]int) []int {
if len(matrix) == 0 || len(matrix[0]) == 0 {
return []int{}
}
var (
rows, columns = len(matrix), len(matrix[0])
order = make([]int, rows * columns)
index = 0
left, right, top, bottom = 0, columns -1 , 0 , rows -1
)
for left <= right && top <= bottom {
// 打印最上层(包含top行最后一个)
for col := left; col <= right; col ++ {
order[index] = matrix[top][col]
index++
}
// 打印最右边(包含最右列最后一个)
for row := top + 1; row <= bottom; row ++ {
order[index] = matrix[row][right]
index++
}
//
if left < right && top < bottom {
// 打印最下边(不包含bottom行最后一个和第一个)
for col := right - 1; col > left; col -- {
order[index] = matrix[bottom][col]
index++
}
// 打印最左边(不包含left列最后一个)
for row := bottom; row > top; row -- {
order[index] = matrix[row][left]
index++
}
}
}
left ++
right --
top ++
bottom --
return order
}No.42 接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
func trap(height []int) int {
if len(height) <= 2 {
return 0
}
// 初始化左右指针
left, right := 0, len(height)-1
// 初始化左右最大高度
leftMax, rightMax := 0, 0
// 初始化雨水总量
totalWater := 0
for left < right {
// 更新左边的最大高度
if height[left] > leftMax {
leftMax = height[left]
}
if height[right] > rightMax {
rightMax = height[right]
}
// 根据短板决定处理那一侧
if leftMax <= rightMax {
// 左边是短板,计算左边的雨水量
totalWater += leftMax - height[left]
left ++
} else {
// 右边是短板,计算右边的雨水量
totalWater += rightMax - height[right]
right --
}
}
return totalWater
}No.46 全排列
给定一个不含重复数字的整数数组 nums ,返回其 所有可能的全排列 。可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
这道题用面向对象的方法比较容易理解 回溯法
type PermState struct {
nums []int // 输入数组
currentPerm []int // 当前正在构建的排列
usedNums map[int]bool // 标记哪些数字在使用
allPerms [][]int // 存储所有完成的排列
}
func NewPermState(nums []int) *PermState {
return &PermState{
nums: nums,
currentPerm: []int{},
usedNums: make(map[int]bool),
allPerms: make([][]int, 0),
}
}
func (ps *PermState) Add(i int) {
ps.currentPerm = append(ps.currentPerm, ps.nums[i])
ps.usedNums[i] = true
}
func (ps *PermState) Remove(i int) {
ps.currentPerm = ps.currentPerm[:len(ps.currentPerm)-1]
ps.usedNums[i] = false
}
func (ps *PermState) CanUse(i int) bool {
return !ps.usedNums[i]
}
func (ps *PermState) IsComplete() bool {
return len(ps.currentPerm) == len(ps.nums)
}
func (ps *PermState) Save() {
temp := make([]int, len(ps.currentPerm))
copy(temp, ps.currentPerm)
ps.allPerms = append(ps.allPerms, temp)
}
func (ps *PermState) BuildPerm() {
if ps.IsComplete() {
ps.Save()
return
}
for i := 0; i < len(ps.nums); i ++ {
if ps.CanUse(i) {
ps.Add(i)
ps.BuildPerm()
ps.Remove(i)
}
}
}
func permute(nums []int) [][]int {
ps := NewPermState(nums)
ps.BuildPerm()
return ps.allPerms
}No.49 字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
输入: strs = [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
输出: [[“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]]
解释:
- 在 strs 中没有字符串可以通过重新排列来形成
"bat"。- 字符串
"nat"和"tan"是字母异位词,因为它们可以重新排列以形成彼此。- 字符串
"ate","eat"和"tea"是字母异位词,因为它们可以重新排列以形成彼此。
func groupAnagrams(strs []string) [][]string {
anagramMap := make(map[string][]string)
for _, str := range strs {
// 将字符串转换为 rune 切片并排序
sorted := sortString(str)
// 按排序后的字符串作为 key 存入 map
anagramMap[sorted] = append(anagramMap[sorted], str)
}
// 收集结果
result := make([][]string, 0, len(anagramMap))
for _, group := range anagramMap {
result = append(result, group)
}
return result
}
// sortString 对字符串按字典序排序
func sortString(s string) string {
runes := strings.Split(s, "")
sort.Strings(runes)
return strings.Join(runes, "")
}No.56 合并区间
输入:intervals = [[1,3],[2,6],[8,10],[15,18]] 输出:[[1,6],[8,10],[15,18]] 解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
// merge 合并重叠的区间
func merge(intervals [][]int) [][]int {
// 边界情况处理
if len(intervals) <= 1 {
return intervals
}
// 按照区间起始位置排序
sort.Slice(intervals, func(i, j int) bool {
return intervals[i][0] < intervals[j][0]
})
// 初始化结果数组,将第一个区间加入
result := [][]int{intervals[0]}
// 遍历剩余区间
for i := 1; i < len(intervals); i++ {
current := intervals[i]
last := result[len(result)-1]
// 如果当前区间与最后一个合并区间重叠
if current[0] <= last[1] {
// 合并区间:更新结束位置为两者的最大值
last[1] = max(last[1], current[1])
} else {
// 不重叠,直接添加当前区间
result = append(result, current)
}
}
return result
}No.106 多数元素
- 链接:https://leetcode.cn/problems/majority-element/
- 思路:摩尔投票算法
给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入:nums = [3,2,3]
输出:3
func majorityElement(nums []int) int {
if len(nums) == 0 {
return 0
}
if len(nums) == 1 {
return nums[0]
}
major := nums[0]
count := 1
for i := 1; i < len(nums); i++ {
if nums[i] == major {
count++
} else {
count--
}
if count < 0 {
count = 1
major = nums[i]
}
}
count = 0
for i := 0; i < len(nums); i++ {
if major == nums[i] {
count += 1
}
}
if count >= len(nums)/2 {
return major
}
return 0
}No.128 最长连续序列
- 链接: https://leetcode.cn/problems/longest-consecutive-sequence/
- 思路:使用哈希表存储所有数字,只从连续序列的起始点(即不存在num-1的数字)开始计算长度,避免重复计算。时间复杂度O(n),空间复杂度O(n)。
给定一个未排序的整数数组
nums,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。请你设计并实现时间复杂度为
O(n)的算法解决此问题。输入:nums = [100,4,200,1,3,2] 输出:4 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
func longestConsecutive(nums []int) int {
if len(nums) == 0 {
return 0
}
// 使用map模拟set,存储所有数字
numSet := make(map[int]bool)
for _, num := range nums {
numSet[num] = true
}
maxLength := 0
// 遍历每个数字
for num := range numSet {
// 只从连续序列的起始点开始计算
if !numSet[num-1] {
currentNum := num
currentLength := 1
// 向右延伸,找连续的数字
for numSet[currentNum+1] {
currentNum++
currentLength++
}
// 更新最大长度
if currentLength > maxLength {
maxLength = currentLength
}
}
}
return maxLength
}No.146 LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现
LRUCache类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。函数
get和put必须以O(1)的平均时间复杂度运行。
// 双向链表节点
type Node struct {
key, value int
prev, next *Node
}
type LRUCache struct {
capacity int
cache map[int]*Node
head *Node // 虚拟头节点
tail *Node // 虚拟尾节点
}
func Constructor(capacity int) LRUCache {
lru := LRUCache{
capacity: capacity,
cache: make(map[int]*Node),
head: &Node{},
tail: &Node{},
}
// 初始化双向链表
lru.head.next = lru.tail
lru.tail.prev = lru.head
return lru
}
// 添加节点到头部
func (lru *LRUCache) addToHead(node *Node) {
node.prev = lru.head
node.next = lru.head.next
lru.head.next.prev = node
lru.head.next = node
}
// 移除节点
func (lru *LRUCache) removeNode(node *Node) {
node.prev.next = node.next
node.next.prev = node.prev
}
// 移动节点到头部
func (lru *LRUCache) moveToHead(node *Node) {
lru.removeNode(node)
lru.addToHead(node)
}
// 移除尾部节点
func (lru *LRUCache) removeTail() *Node {
lastNode := lru.tail.prev
lru.removeNode(lastNode)
return lastNode
}
func (lru *LRUCache) Get(key int) int {
if node, exists := lru.cache[key]; exists {
// 移动到头部表示最近使用
lru.moveToHead(node)
return node.value
}
return -1
}
func (lru *LRUCache) Put(key int, value int) {
if node, exists := lru.cache[key]; exists {
// 更新值并移动到头部
node.value = value
lru.moveToHead(node)
} else {
newNode := &Node{key: key, value: value}
if len(lru.cache) >= lru.capacity {
// 超出容量,删除尾部节点
tail := lru.removeTail()
delete(lru.cache, tail.key)
}
// 添加新节点到头部
lru.cache[key] = newNode
lru.addToHead(newNode)
}
}No.169
给定一个大小为
n的数组nums,返回其中的多数元素。多数元素是指在数组中出现次数 大于⌊ n/2 ⌋的元素。你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入:nums = [3,2,3] 输出:3示例 2:
输入:nums = [2,2,1,1,1,2,2] 输出:2
No.200 岛屿数量
给你一个由
'1'(陆地)和'0'(水)组成的的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [ ["1","1","1","1","0"], ["1","1","0","1","0"], ["1","1","0","0","0"], ["0","0","0","0","0"] ] 输出:1
func numIslands(grid [][]byte) int {
if len(grid) == 0 || len(grid[0]) == 0 {
return 0
}
rows, cols := len(grid), len(grid[0])
count := 0
// DFS函数,将相连的陆地标记为已访问
var dfs func(int, int)
dfs = func(i, j int) {
// 边界检查和水域检查
if i < 0 || i >= rows || j < 0 || j >= cols || grid[i][j] == '0' {
return
}
// 标记为已访问
grid[i][j] = '0'
// 递归访问四个方向
dfs(i-1, j) // 上
dfs(i+1, j) // 下
dfs(i, j-1) // 左
dfs(i, j+1) // 右
}
// 遍历整个网格
for i := 0; i < rows; i++ {
for j := 0; j < cols; j++ {
if grid[i][j] == '1' {
count++
dfs(i, j) // 将整个岛屿标记为已访问
}
}
}
return count
}No.209 长度最小的子数组
- 链接:https://leetcode.cn/problems/minimum-size-subarray-sum/description/
- 思路:其题意是在数组中找到满足 连续 、子数组和大于target和 数量最少 三个条件的子数组,由连续就能快速联想并对应到滑动窗口的概念。
func minSubArrayLen(target int, nums []int) int {
ri := 0 // 右指针
minLength := math.MaxInt
if len(nums) == 0 {
return 0
}
curSize := 0
// 移动左指针
for i := 0 ; i < len(nums); i ++ {
if i != 0 {
curSize -= nums[i-1]
}
// 移动右指针。当前Size >= target就退出
for ri < len(nums) && nums[ri] + curSize < target {
curSize += nums[ri]
ri ++
}
// 是我们想要的退出时机,而不是ri遍历完了
if ri < len(nums) && curSize + nums[ri] >= target {
if ri + 1 - i < minLength {
minLength = ri + 1 -i
}
}
}
if minLength == math.MaxInt {
return 0
}
return minLength
}第二种写法,也是标准的滑动窗口。
func minSubArrayLen(target int, nums []int) int {
var count int = math.MaxInt64
var targetList []int
var right int
for left := 0; left < len(nums); left++ {
// 持续移动窗口的左边,直到窗口中的数组之和不满足和大于target
for len(targetList) > 0 {
// 找到最小
if sum(targetList) >= target && len(targetList) <= count {
count = len(targetList)
} else {
break
}
// 逐渐左移下标
targetList = targetList[1:]
}
// 移动滑动窗口的右边界
for ; right < len(nums); right++ {
targetList = append(targetList, nums[right])
if sum(targetList) < target {
continue
} else {
// 能到这里表示滑动窗口里的值是满足要求的,右指针再往右一格
if len(targetList) <= count {
count = len(targetList)
}
right++
break
}
}
}
if count == math.MaxInt64 {
return 0
}
return count
}
func sum(list []int) int {
all := 0
for _, v := range list {
all += v
}
return all
}No.215 数组中的第K个最大元素
链接: https://leetcode.cn/problems/kth-largest-element-in-an-array/description/
思路:
- 提供两种解法:
- 快速选择算法:基于快排的分区思想,平均时间复杂度O(n),最坏O(n²)但通过随机化pivot可避免
- 小根堆:维护大小为k的小根堆,时间复杂度O(nlogk),空间复杂度O(k)
快速选择是最优解,将找第k大元素转换为找第(n-k)小元素,通过分区操作逐步缩小搜索范围。
给定整数数组
nums和整数k,请返回数组中第**k**个最大的元素。请注意,你需要找的是数组排序后的第
k个最大的元素,而不是第k个不同的元素。你必须设计并实现时间复杂度为
O(n)的算法解决此问题。示例 1:
输入: [3,2,1,5,6,4], k = 2 输出: 5示例 2:
输入: [3,2,3,1,2,4,5,5,6], k = 4 输出: 4
func findKthLargest(nums []int, k int) int {
// 将问题转换为找第 len(nums) - k 小的元素
return quickSelect(nums, 0, len(nums)-1, len(nums)-k)
}
func quickSelect(nums []int, left, right, k int) int {
if left == right {
return nums[left]
}
// 随机选择pivot避免最坏情况
rand.Seed(time.Now().UnixNano())
pivotIndex := left + rand.Intn(right-left+1)
// 分区操作
pivotIndex = partition(nums, left, right, pivotIndex)
if k == pivotIndex {
return nums[k]
} else if k < pivotIndex {
return quickSelect(nums, left, pivotIndex-1, k)
} else {
return quickSelect(nums, pivotIndex+1, right, k)
}
}
func partition(nums []int, left, right, pivotIndex int) int {
pivotValue := nums[pivotIndex]
// 将pivot移到末尾
nums[pivotIndex], nums[right] = nums[right], nums[pivotIndex]
storeIndex := left
// 将小于pivot的元素移到左边
for i := left; i < right; i++ {
if nums[i] < pivotValue {
nums[storeIndex], nums[i] = nums[i], nums[storeIndex]
storeIndex++
}
}
// 将pivot放到正确位置
nums[right], nums[storeIndex] = nums[storeIndex], nums[right]
return storeIndex
}
// 使用小根堆的解法(时间复杂度O(nlogk))
func findKthLargestHeap(nums []int, k int) int {
// 维护大小为k的小根堆
heap := make([]int, 0, k)
for _, num := range nums {
if len(heap) < k {
heap = append(heap, num)
heapifyUp(heap, len(heap)-1)
} else if num > heap[0] {
heap[0] = num
heapifyDown(heap, 0)
}
}
return heap[0]
}
func heapifyUp(heap []int, i int) {
for i > 0 {
parent := (i - 1) / 2
if heap[i] >= heap[parent] {
break
}
heap[i], heap[parent] = heap[parent], heap[i]
i = parent
}
}
func heapifyDown(heap []int, i int) {
n := len(heap)
for {
smallest := i
left, right := 2*i+1, 2*i+2
if left < n && heap[left] < heap[smallest] {
smallest = left
}
if right < n && heap[right] < heap[smallest] {
smallest = right
}
if smallest == i {
break
}
heap[i], heap[smallest] = heap[smallest], heap[i]
i = smallest
}
}No.239 滑动窗口最大值
链接:https://leetcode.cn/problems/sliding-window-maximum/description/
思路:使用单调递减双端队列维护滑动窗口最大值。队列存储数组下标,队首始终是当前窗口的最大值下标。移除窗口外元素和队尾较小元素,保持单调性。时间复杂度O(n),空间复杂度O(k)。
给你一个整数数组
nums,有一个大小为k的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的k个数字。滑动窗口每次只向右移动一位。返回 滑动窗口中的最大值 。
示例 1:
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 输出:[3,3,5,5,6,7] 解释: 滑动窗口的位置 最大值 --------------- ----- [1 3 -1] -3 5 3 6 7 3 1 [3 -1 -3] 5 3 6 7 3 1 3 [-1 -3 5] 3 6 7 5 1 3 -1 [-3 5 3] 6 7 5 1 3 -1 -3 [5 3 6] 7 6 1 3 -1 -3 5 [3 6 7] 7
func maxSlidingWindow(nums []int, k int) []int {
if len(nums) == 0 || k == 0 {
return []int{}
}
result := make([]int, 0, len(nums)-k+1)
// 双端队列,存储数组下标
deque := make([]int, 0)
for i := 0; i < len(nums); i++ {
// 移除窗口外的元素
for len(deque) > 0 && deque[0] <= i-k {
deque = deque[1:]
}
// 维持单调递减队列:移除队尾小于当前元素的下标
for len(deque) > 0 && nums[deque[len(deque)-1]] < nums[i] {
deque = deque[:len(deque)-1]
}
// 当前元素下标入队
deque = append(deque, i)
// 窗口形成后,队首就是当前窗口的最大值
if i >= k-1 {
result = append(result, nums[deque[0]])
}
}
return result
}No.238 移动零
- 链接: https://leetcode.cn/problems/move-zeroes/
- 思路:使用双指针算法:left指针标记下一个非零元素的放置位置,right指针遍历数组。将非零元素依次移到前面,然后将剩余位置填0。优化版本通过交换减少不必要的赋值操作。时间复杂度O(n),空间复杂度O(1)。
给定一个数组
nums,编写一个函数将所有0移动到数组的末尾,同时保持非零元素的相对顺序。请注意 ,必须在不复制数组的情况下原地对数组进行操作。
示例 1:
输入: nums = [0,1,0,3,12] 输出: [1,3,12,0,0]示例 2:
输入: nums = [0] 输出: [0]
func moveZeroes(nums []int) {
// 双指针:left指向下一个非零元素应该放置的位置
left := 0
// 第一遍:将所有非零元素移到前面
for right := 0; right < len(nums); right++ {
if nums[right] != 0 {
nums[left] = nums[right]
left++
}
}
// 第二遍:将剩余位置填充为0
for left < len(nums) {
nums[left] = 0
left++
}
}
// 优化版本:减少赋值操作
func moveZeroesOptimized(nums []int) {
left := 0
for right := 0; right < len(nums); right++ {
if nums[right] != 0 {
// 只在需要交换时才进行操作
if left != right {
nums[left], nums[right] = nums[right], nums[left]
}
left++
}
}
}No.415 字符串相加
- 链接:https://leetcode.cn/problems/add-strings/
- 采用末尾向前递进的方式
func addStrings(num1 string, num2 string) string {
i, j := len(num1)-1, len(num2)-1
carry := 0
result := ""
for i >= 0 || j >= 0 || carry != 0 {
var x, y int
if i >= 0 {
x = int(num1[i] - '0') // 了把字符形式的数字转化成对应的整数值,需要用该字符的 ASCII 码值减去字符 '0' 的 ASCII 码值。
}
if j >= 0 {
y = int(num2[j] - '0')
}
sum := x + y + carry
carry = sum / 10
digit := sum % 10
result = strconv.Itoa(digit) + result
i--
j--
}
return result
}No.459 重复的子字符串
- 链接:https://leetcode.cn/problems/repeated-substring-pattern/submissions/
- 原题:给定一个非空的字符串
s,检查是否可以通过由它的一个子串重复多次构成。 - 思路:先第一重循环,找出子串。子串的头已经有了,就是字符串的第一个元素,所以移动下标找末尾元素即可。再到第二个循环中从子串长度开始循环,遍历完整个字符串。
func repeatedSubstringPattern(s string) bool {
// 获取字符串 s 的长度
length := len(s)
// 遍历可能的子字符串长度,子字符串长度范围从 1 到 length/2
for subLen := 1; subLen*2 <= length; subLen++ {
// 检查字符串长度是否能被子字符串长度整除
if length%subLen == 0 {
// 如果能整除,检查是否由该子字符串重复构成
if isRepeatedBySubstring(s, subLen) {
return true
}
}
}
// 没有找到符合条件的子字符串,返回 false
return false
}
// isRepeatedBySubstring 检查字符串 s 是否由长度为 subLen 的子字符串重复构成
func repeatedSubstringPattern(s string) bool {
n := len(s)
if n == 0 {
return false // 空字符串不符合条件
}
// 拼接两个 s
ss := s + s
// 查找 s 是否存在于 ss[1 : 2*n-1] 中
// strings.Contains 效率较高,因为它内部通常会使用优化的字符串查找算法
// 这里的 ss[1:2*n-1] 是为了排除 s 本身在 ss 中的起始位置和结束位置
// 例如 "abab" + "abab" = "abababab"
// 排除首尾字符后是 "bababa"
// 在 "bababa" 中查找 "abab",如果找到则说明是重复子串
return strings.Contains(ss[1:2*n-1], s)
}解法二:如果将字符串叠加,再移除头部和尾部的字符串,如果是重复的,一定可以在合并字符串中找到原本的自己。
func repeatedSubstringPattern(s string) bool {
return strings.Index((s + s)[1:len(s)*2-1], s) != -1
}No.438 找到字符串中所有字母异位词
给定两个字符串
s和p,找到s中所有p的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。示例 1:
输入: s = "cbaebabacd", p = "abc" 输出: [0,6] 解释: 起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。 起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。示例 2:
输入: s = "abab", p = "ab" 输出: [0,1,2] 解释: 起始索引等于 0 的子串是 "ab", 它是 "ab" 的异位词。 起始索引等于 1 的子串是 "ba", 它是 "ab" 的异位词。 起始索引等于 2 的子串是 "ab", 它是 "ab" 的异位词。
No.560 和位K的子数组
- 链接:https://leetcode.cn/problems/subarray-sum-equals-k/description/
- 思路:使用前缀和+哈希表:如果当前前缀和为sum,存在前缀和为(sum-k),则它们之间的子数组和为k。时间复杂度O(n),空间复杂度O(n)。
给你一个整数数组
nums和一个整数k,请你统计并返回 该数组中和为k的子数组的个数 。子数组是数组中元素的连续非空序列。
示例 1:
输入:nums = [1,1,1], k = 2 输出:2示例 2:
输入:nums = [1,2,3], k = 3 输出:2
func subarraySum(nums []int, k int) int {
count := 0
prefixSum := 0
// 前缀和哈希表,key为前缀和,value为出现次数
sumMap := map[int]int{0: 1} // 初始化,前缀和为0出现1次
for _, num := range nums {
prefixSum += num
// 如果存在前缀和为(prefixSum - k),说明存在和为k的子数组
if count, exists := sumMap[prefixSum-k]; exists {
count += count
}
// 更新当前前缀和的出现次数
sumMap[prefixSum]++
}
return count
}No.674 最长连续递增序列
- 链接:https://leetcode.cn/problems/longest-continuous-increasing-subsequence/
- 思路:一次遍历,找最长,存下来
func findLengthOfLCIS(nums []int) int {
if len(nums) == 0 {
return 0
}
maxLength := 1
currentLength := 1
for i := 1; i < len(nums); i++ {
// 下一个更大,这里长度+1
if nums[i] > nums[i-1] {
currentLength++
} else {
maxLength = max(maxLength, currentLength)
currentLength = 1
}
}
// 处理最后一个递增子序列的情况
maxLength = max(maxLength, currentLength)
return maxLength
}链表
No.2 两数相加
func addTwoNumbers(l1, l2 *ListNode) (head *ListNode) {
var tail *ListNode
carry := 0
for l1 != nil || l2 != nil {
n1, n2 := 0, 0
if l1 != nil {
n1 = l1.Val
l1 = l1.Next
}
if l2 != nil {
n2 = l2.Val
l2 = l2.Next
}
sum := n1 + n2 + carry
sum, carry = sum%10, sum/10
if head == nil {
head = &ListNode{Val: sum}
tail = head
} else {
tail.Next = &ListNode{Val: sum}
tail = tail.Next
}
}
if carry > 0 {
tail.Next = &ListNode{Val: carry}
}
return
}No.21 合并两个链表
func mergeTwoLists(l1 *ListNode, l2 *ListNode) *ListNode {
tmp := &ListNode{}
prev := tmp
for l1 != nil && l2 != nil {
if l1.Val < l2.Val{
prev.Next = l1
prev = prev.Next
l1 = l1.Next
}else {
prev.Next = l2
prev = prev.Next
l2 = l2.Next
}
}
if l2 != nil {
prev.Next = l2
}
if l1 != nil {
prev.Next = l1
}
return tmp.Next
}No.22 链表的倒数第k个节点
- 链接:https://leetcode.cn/problems/lian-biao-zhong-dao-shu-di-kge-jie-dian-lcof/
- 思路1:将节点全部保存到列表里,再返回索引,当然这个方法费空间。思路2:快慢指针。即 fast、slow 两个指针,fast 先移动k步,再slow和fast一起移动,当fast遍历结束时,slow就是倒数第k步。
// 非常low的写法
func getKthFromEnd(head *ListNode, k int) *ListNode {
var rest []*ListNode
for node := head; node != nil; node = node.Next {
rest = append(rest, node)
}
if len(rest) >= k {
return rest[len(rest) - k]
}
return nil
}
// 快慢指针
func getKthFromEnd(head *ListNode, k int) *ListNode {
fast, slow := head, head
for fast != nil && k > 0 {
fast = fast.Next
k--
}
for fast != nil {
fast = fast.Next
slow = slow.Next
}
return slow
}No.25 K个一组翻转链表
- 链接:https://leetcode.cn/problems/reverse-nodes-in-k-group/description/
- 思路:其实很简单,只要会链表翻转就会K个一组翻转。写一个翻转函数,将头部K个翻转,K个后面的再拼回来。循环此过程
func reverseKGroup(head *ListNode, k int) *ListNode {
if head == nil || k <= 1 {
return head
}
dummy := &ListNode{}
moved := dummy
for head != nil {
// head next
tail := head
for i := 0; i < k && tail != nil; i++ {
tail = tail.Next
}
if tail == nil {
break
}
// 记录下一组的起始节点
nextGroup := tail.Next
newHead, newTail := reverseKNode(head, k)
moved.Next = newHead
newTail.Next = nextGroup
moved = newTail
head = nextGroup
}
return dummy.Next
}
func reverseKNode(head *ListNode, k int) (*ListNode, *ListNode) {
var prev *ListNode = nil
var cur *ListNode = head
for i := 0; i < k && cur != nil; i++ {
next := cur.Next
cur.Next = prev
prev = cur
cur = next
}
// head 是原先的链表头,反转后,是链表的尾部
return prev, head
}No.83 删除排序链表重复项
- 链接:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-list/
- 思路1:题解感觉和我差不太多,我的思路是先把重复项移到尾端,然后cur 指针指向重复项的尾端就好了。但不知道为啥 8ms 打败 7.3% 。理论就是 O(N) 啊。
func deleteDuplicates(head *ListNode) *ListNode {
if head == nil {
return nil
}
newHead := head
moved := newHead
for head != nil {
// 找到下一个不同值的节点
for head.Next != nil && head.Val == head.Next.Val {
head = head.Next
}
// 连接不重复的节点
moved.Next = head.Next
moved = moved.Next
head = head.Next
}
return newHead
}No.92 翻转局部链表
- 链接:https://leetcode.cn/problems/reverse-linked-list-ii/description/
- 思路:取前半部分,再写一个链表翻转的函数,最后将后半部分接上。这里可以把链表翻转抽象出来。
func reverseBetween(head *ListNode, left int, right int) *ListNode {
if head == nil {
return nil
}
length := right - left
tmp := &ListNode{}
tmp.Next = head
cur := tmp
// 将指针移动到翻转的前半部分
for head != nil && left - 1 > 0 {
next := head.Next
cur.Next = head
cur = cur.Next
head = next
left --
}
next := head
cur.Next = reverseList(next, length+1)
return tmp.Next
}
// 生成翻转和翻转的后半部分
func reverseList(head *ListNode, length int) *ListNode {
if head == nil || length <= 0 {
return head
}
var prev *ListNode = nil
var cur *ListNode = prev
for head != nil && length > 0 {
next := head.Next
head.Next = prev
cur = head
prev = cur
length --
head = next
}
next := head
tmp := cur
for tmp.Next != nil {
tmp = tmp.Next
}
tmp.Next = next
return cur
}思路二:简单的看,将列表拆成3部分,第一部分是0-left,不需要反转,第二部分是 left-right 需要反转,right 之后的部分。
func reverseBetween(head *ListNode, left int, right int) *ListNode {
group := &ListNode{}
groupMoved := group
// 获取 0-left 部分,group1 是前半部分,newHead 是后半部分
group1, newHead := getListByIndex(head, left-1)
head = newHead
groupMoved.Next = group1
for groupMoved.Next != nil { // 指针前进
groupMoved = groupMoved.Next
}
// 获取 left-right 部分
group2, newHead := getListByIndex(head, right-left+1)
reverseGroup := reverse(group2)
groupMoved.Next = reverseGroup
for groupMoved.Next != nil { // 指针前进
groupMoved = groupMoved.Next
}
groupMoved.Next = newHead
return group.Next
}
func getListByIndex(head *ListNode, k int) (*ListNode, *ListNode) {
if head == nil || k <= 0 {
return nil, head
}
// 获取前N个节点
front := head
current := head
for i := 1; i < k && current != nil; i++ {
current = current.Next
}
// 如果不足N个节点
if current == nil {
return head, nil
}
// 分割链表
back := current.Next
current.Next = nil // 断开连接
return front, back
}
// 反转函数
func reverse(head *ListNode) *ListNode {
var tail *ListNode
moved := tail
for head != nil {
next := head.Next
movedNext := moved
moved = head
moved.Next = movedNext
head = next
}
return moved
}No.141 环形链表
- 链接: https://leetcode-cn.com/problems/linked-list-cycle/
- 思路1:这道题思路非常简单,就是快慢指针,慢指针每次前进一步,快指针每次前进两步。如果存在环快指针一定会追上慢指针,问题就是边界条件太多,需要仔细判断。
- 思路2:hash表存已有的数据做对比,这个最简单,不演示啦~
func hasCycle(head *ListNode) bool {
if head == nil {
return false
}
slow := head
fast := head.Next
for fast != nil && fast.Next != nil {
slow = slow.Next
fast = fast.Next.Next
if slow == fast {
return true
}
}
return false
}No.148 排序链表
- 链接:https://leetcode.cn/problems/sort-list/
- 思路:这道题采用归并排序的方法,将链表拆成足够小的部分,然后排序,就相当于是有序链表的合并,而拆到足够细时,因为链表就一个值,所以当然是有序的
func sortList(head *ListNode) *ListNode {
return sort(head, nil)
}
func sort(head *ListNode, tail *ListNode) *ListNode {
if head == nil {
return nil
}
// 拆到足够细了,就是链表的一个节点
if head.Next == tail {
head.Next = nil
return head
}
fast := head
slow := head
for fast.Next != tail {
fast = fast.Next
slow = slow.Next
if fast.Next != tail {
fast = fast.Next
}
}
return merge(sort(head, slow), sort(slow, tail))
}
// 有序链表的合并
func merge(p, q *ListNode) *ListNode {
if p == nil {
return q
}
if q == nil {
return p
}
tmp := &ListNode{}
cur := tmp
for p != nil && q != nil {
if p.Val > q.Val {
cur.Next = &ListNode{Val: q.Val, Next: nil}
q = q.Next
} else {
cur.Next = &ListNode{Val: p.Val, Next: nil}
p = p.Next
}
cur = cur.Next
}
if p != nil {
cur.Next = p
} else {
cur.Next = q
}
return tmp.Next
}No.160 相交链表
- 链接:https://leetcode.cn/problems/intersection-of-two-linked-lists/
- 思路:可以直接将所有节点存到 hash 表中。
func getIntersectionNode(headA, headB *ListNode) *ListNode {
tmp := make(map[*ListNode]struct{})
for headA != nil {
tmp[headA] = struct{}{}
headA = headA.Next
}
for headB != nil {
if _, ok := tmp[headB]; ok {
return headB
}
headB = headB.Next
}
return nil
}No.203 移除链表元素
- 链接:https://leetcode.cn/problems/remove-linked-list-elements/
- 思路:很简单呐,就是双循环,里面那层循环遇到相等的就往后移动
func removeElements(head *ListNode, val int) *ListNode {
if head == nil {
return nil
}
tmp := &ListNode{}
prev := tmp
for head != nil {
for head != nil && head.Val == val {
head = head.Next
}
prev.Next = head
prev = prev.Next
if head != nil {
head = head.Next
}
}
return tmp.Next
}或者可以这么写, 思维逻辑清晰,不过追加这块是一直在创建新的Node,不是复用Head的
func removeElements(head *ListNode, val int) *ListNode {
tmp := &ListNode{}
moved := tmp
for head != nil {
if head.Val != val {
moved.Next = &ListNode{Val: head.Val}
moved = moved.Next
}
head = head.Next
}
return tmp.Next
}No.206 反转链表
- 链接:https://leetcode-cn.com/problems/reverse-linked-list/
- 思路1:双指针 本质还是遍历 head, 上面的
next := head.Next和下面的head = next就是为了遍历, 中间的三行是 当前head的节点的下一个指向之前,cur即为当前head节点,cur 成为历史 prev
func reverseList(head *ListNode) *ListNode {
if head == nil {
return nil
}
var prev *ListNode = nil
cur := prev
for head != nil {
next := head.Next // 存下一个
head.Next = prev // haed 的Next指向 prev
cur = head // cur 就是 head
prev = cur // cur 成为 prev
head = next // head 前进
}
return cur
}或者这么写,其实逻辑也很清晰
func reverseList(head *ListNode) *ListNode {
var tail *ListNode = nil
for head != nil {
next := head.Next
nextTail := tail
tail = head
tail.Next = nextTail
head = next
}
return tail
}No.234 回文链表
- 链接:https://leetcode.cn/problems/palindrome-linked-list/
- 思路:这道题很奇怪,就是遍历链表,赋值到数组中,再循环判断。
func isPalindrome(head *ListNode) bool {
var vals []int
for ; head != nil; head = head.Next {
vals = append(vals, head.Val)
}
n := len(vals)
for i, v := range vals[:n/2] {
if v != vals[n-1-i] {
return false
}
}
return true
}实现一个 LRU 缓存
package lru
import (
"container/list"
"errors"
)
const (
MemoryOverFlow int = 0
MemorySizeError int = 1
NotFoundObject int = 11
)
var lruErrorName = map[int]string{
MemoryOverFlow: "MemoryOverFlow",
MemorySizeError: "MemorySizeError",
NotFoundObject: "NotFoundObject",
}
// 记录存储数据的大小
type Value interface {
Len() int64
}
// 存储的对象
type entry struct {
key string
value Value
}
type Cache struct {
maxBytes int64 // 最大使用内存
nBytes int64 // 当前已使用内存
ll *list.List // 链表存储淘汰关系
cache map[string]*list.Element //节点放到字典中,加速查找
OnEvicted func(key string, value Value) //某条记录被删除时候的回调函数
}
func CreateLRUCache(maxByte int64,evicted func(string,Value)) *Cache {
return &Cache{
maxBytes: maxByte,
nBytes: 0,
ll: new(list.List),
cache: make(map[string]*list.Element),
OnEvicted: evicted,
}
}
func (c *Cache) Get(key string) (value Value,err error) {
if ele, ok := c.cache[key]; ok {
c.ll.MoveToFront(ele)
return ele.Value.(*entry).value, nil
}else {
return nil, errors.New(lruErrorName[NotFoundObject])
}
}
func (c *Cache) Add(key string, value Value) error {
// 判断是否可以加入(太大会把所有缓存冲掉)
if c.isOutOfMaxMemory(value.Len()) {
return errors.New(lruErrorName[MemoryOverFlow]) // 内存不足以添加该缓存
}
// 判断缓存中已有该键, 更新
if v, ok := c.cache[key]; ok {
oldValue := v.Value.(*entry)
// 可以加入,将该键移动到队头
c.ll.MoveToFront(v)
c.cache[oldValue.key] = &list.Element{Value: &entry{key,value}}
c.nBytes = c.nBytes - oldValue.value.Len() + value.Len()
return nil
}
// 没有该键,第一次添加
ele := c.ll.PushFront(&entry{key, value})
c.cache[key] = ele
c.nBytes = c.nBytes + value.Len()
// 若内存不够,需要循环删除掉最老的
for c.maxBytes != 0 && c.maxBytes < c.nBytes {
if err := c.RemoveOldest(); err != nil {
return err
}
}
return nil
}
func (c *Cache) RemoveOldest() error {
oldest := c.ll.Back()
if oldest != nil {
oldestEntry := oldest.Value.(*entry)
c.ll.Remove(oldest) // 删除链表节点
c.nBytes = c.nBytes - oldestEntry.value.Len() // 删除字节长度
delete(c.cache, oldestEntry.key) // 删除字典
if c.nBytes < 0 {
return errors.New(lruErrorName[MemorySizeError])
}
if c.OnEvicted != nil {
c.OnEvicted(oldestEntry.key, oldestEntry.value)
}
}
return nil
}
func (c *Cache) Len() int64 {
return int64(c.ll.Len())
}
func (c *Cache) isOutOfMaxMemory(size int64) bool {
return size > c.maxBytes测试
type GeeByte struct {
Value []byte
}
func (g GeeByte) Len() int64 {
return int64(len(g.Value))
}
func TestLruCache(t *testing.T) {
lruObject := lru.CreateLRUCache(20, func(key string, value lru.Value) {
fmt.Printf("%s 被删除了, 释放了 %d 字节的空间\n", key, value.Len())
})
_ = lruObject.Add("key1", GeeByte{[]byte("Hello, Golang")})
_ = lruObject.Add("key2", GeeByte{[]byte("Hello, ByteDance")})
if value, err := lruObject.Get("key2"); err != nil {
log.Fatalln(err)
}else {
fmt.Printf("%s",value)
}
}